简介
1、首先我目前平台上承载的大部分项目是读多写少的项目,而MyISAM的读性能是比Innodb强不少的。
2、MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引,而Innodb是索引和数据是紧密捆绑的,没有使用压缩从而会造成Innodb比MyISAM体积庞大不小。
4、从我接触的应用逻辑来说,select count(*) 和order by 是最频繁的,大概能占了整个sql总语句的60%以上的操作,而这种操作Innodb其实也是会锁表的,很多人以为Innodb是行级锁,那个只是 where对它主键是有效,非主键的都会锁全表的。
5、还有就是经常有很多应用部门需要我给他们定期某些表的数据,MyISAM的话很方便,只要发给他们对应那表的frm.MYD,MYI的文 件,让他们自己在对应版本的数据库启动就行,而Innodb就需要导出xxx.sql了,因为光给别人文件,受字典数据文件的影响,对方是无法使用的。
理论分析
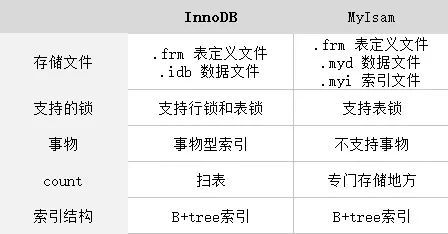
那么为什么大家喜欢说 MyisAM 查询快呢?那是因为,InnoDB 的表是根据主键进行展开的 B+tree 的聚集索引。MyIsam 则非聚集型索引,myisam 存储会有两个文件,一个是索引文件,另外一个是数据文件,其中索引文件中的索引指向数据文件中的表数据。
聚集型索引并不是一种单独的索引类型,而是一种存储方式,InnoDB 聚集型索引实际上是在同一结构中保存了 B+tree 索引和数据行。当有聚簇索引时,它的索引实际放在叶子页中。
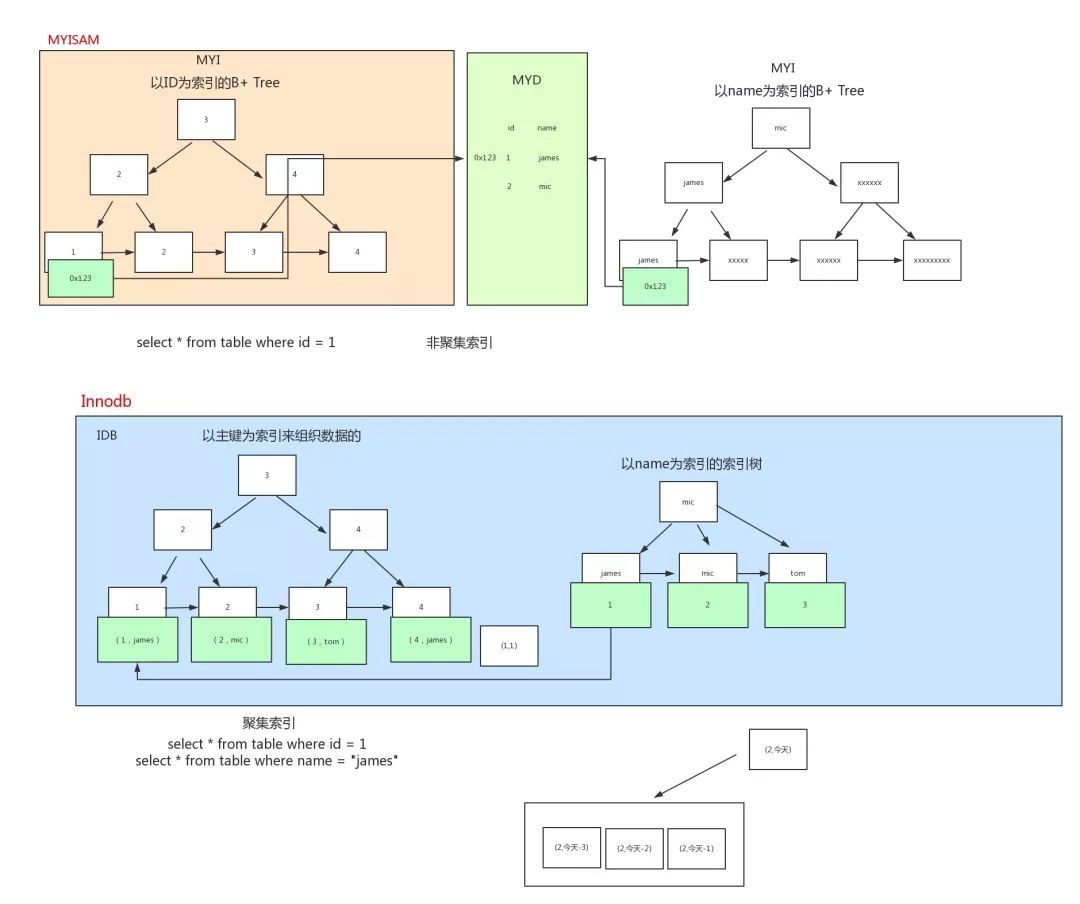
结合上图,可以看出:INNODB 在做 SELECT 的时候,要维护的东西比 MYISAM 引擎多很多。

数据对比
测试方法:连续提交10个query, 表记录总数:38万 , 时间单位 s
引擎类型 Myisam innordb 性能相差
count 0.0008357 3.0163 3609
查询主键 0.005708 0.1574 27.57
查询非主键 24.01 80.37 3.348
更新主键 0.008124 0.8183 100.7
更新非主键 0.004141 0.02625 6.338
插入 0.004188 0.3694 88.21
结论:
1. 加了索引以后,对于Myisam查询可以加快:4 206.09733倍,对innordb 查询加快510.72921倍。同时对myisam更新速度减慢为原来的1/2,innordb的更新速度减慢为原来的1/30。大家要看情况决定是否要加索引,比如不查询的log表,不要做任何的索引。
2. 如果你的数据量是百万级别的,并且没有任何的事务处理,那么用myisam是性能最好的选择。
3. Innordb的表的大小更加的大,用myisam可以省很多的硬盘空间。
在我们测试的这个38w的表中,表占用空间的情况如下:
引擎类型 MyIsam InnorDB
数据 53,924 KB 58,976 KB
索引 13,640 KB 21,072 KB
占用总空间 67,564 KB 80,048 KB
另外一个176W万记录的表, 表占用空间的情况如下:
引擎类型 MyIsam InnorDB
数据 56,166 KB 90,736 KB
索引 67,103 KB 88,848 KB
占用总空间 123,269 KB 179,584 KB
总结
MYisam 适合:
1. 做很多count 的计算。
2. 插入不平凡,查询非常频繁。
3. 没有事务
innordb 非常适合:
1. 可靠性要求比较高,或者要求事务。
2. 表更新和查询都相当的频繁,并且表锁定的机会比较大的情况。
当然这也不是绝对的。要试验过才知道。
很多时候,性能瓶颈不是因为服务器配置不好,而是因为SQL不是很好。SQL的性能优化是关键。
除了这些常见的优化方法,
还可以考虑 使用内存表。你测试一张myisam 和 内存表,会发现速度差不多。
其实,在并发比较强的时候,性能会相差大概五倍。我有张经常要查询的IP 地址 和 地区的 对应表,放入内存后。
以前查询 5000个 IP 地址大概 要 15S, 现在,只要 2S多。
很多东西,实际测试过才知道。用什么压力测试,测试出来的也不是很准确。
来源:
简介:https://blog.csdn.net/iris_xuting/article/details/38586741
理论分析:https://cloud.tencent.com/developer/article/1401129
数据对比:https://dude6.com/article/114149.html
MySQL 聚集索引(Clustered Index)与聚簇索引
聚集索引和聚簇索引实际上是同一个概念的不同中文翻译,英文都是"Clustered Index"。在MySQL中,InnoDB存储引擎使用的就是这种索引结构。
基本概念
聚集索引/聚簇索引是一种将数据存储与索引结构结合在一起的索引方式。它的特点是:
-
索引的叶子节点直接包含完整的数据行
-
表数据本身就是索引结构的一部分
-
一个表只能有一个聚集索引
InnoDB中的实现特点
-
主键即聚集索引:
-
如果表定义了主键,InnoDB会自动使用主键作为聚集索引
-
如果没有显式定义主键,InnoDB会选择第一个UNIQUE NOT NULL的列作为聚集索引
-
如果以上都没有,InnoDB会创建一个隐藏的6字节ROWID作为聚集索引
-
物理存储顺序:
-
性能优势:
-
通过主键查询非常高效(只需一次索引查找)
-
范围查询效率高(相邻数据物理上也相邻)
与非聚集索引(Secondary Index)的区别
| 特性 |
聚集索引 |
非聚集索引(二级索引) |
| 数量 |
每表一个 |
每表多个 |
| 叶子节点内容 |
包含完整数据行 |
只包含主键值 |
| 查询效率 |
主键查询极快 |
需要回表查询(二次查找) |
| 存储方式 |
决定数据物理存储顺序 |
不影响数据物理存储 |
设计建议
-
为InnoDB表设计合适的主键(最好是自增整数)
-
避免使用过长的字段作为主键(会导致二级索引变大)
-
理解"回表"概念,优化查询避免过多回表操作
聚集索引的设计直接影响InnoDB表的存储效率和查询性能,是MySQL数据库设计中非常重要的概念。
「三年博客,如果觉得我的文章对您有用,请帮助本站成长」
admin(6年前 (2020-03-09))
admin(6年前 (2020-03-09))
admin(6年前 (2020-03-09))
一位WordPress评论者(6年前 (2020-02-13))
共有 0 - Myisam 存储引擎的优势